SharePoint has several web-parts that can do cross-list and cross-subsite queries, such as the Content Query web-part, but all restricted to a single site-collection. In addition, there are the classic Data View web-part and the new XSLT List View web-parts that can be configured using SharePoint Designer. These web-parts can connect to a diverse set of data sources, from internal SharePoint lists to external REST and OData services.
Still, the simplest solution for cross-site/cross-solution rollups is to customize the ootb search web-parts against custom search scopes in the Search Service application. In most cases, no coding will be required, pure configuration of SharePoint will go a long way. This post will show how to configure a search driven "My Tasks" web-part that will show all tasks assigned to the user across all SharePoint sites across all indexed SharePoint solutions. The unstyled cross-site task rollup web-part looks like this, included some debug info:

First you need to configure the results scope behind the search driven web-part in Central Admin. Start by adding a new scope in 'Search Service Application>Scopes' called TaskRollup using the rules as shown here:

If you can't see ContentType when adding a rule, then go to 'Search Service Application>Metadata Properties' and edit the managed property to set Allow this property to be used in scopes.
As the TaskStatus site column is not mapped to any managed property by default, you must map the crawled property ows_Status to one before it can be used. Go to 'Search Service Application>Metadata Properties' and create a managed property called TaskStatus using the mapping as shown here:

Do not go creative with the naming, stay away from spaces and special characters such as ÆØÅ - a SharePoint best practice for any artifact name used as an identifier or an URL fragment. For example, a name like "Contoso Web Ingress" first gets encoded as "Contoso_x0020_Web_x0020_Ingress" when stored, and then once more encoded as "Contoso_x005F_x0020_Web_x005F_x0020_Ingress" in a search result XML.
A full crawl is required after adding or changing crawled or managed properties. Do a full crawl of the content source you used in the TaskRollup scope. Note that there must be some matching content stored in SharePoint for these properties to be added to the property database in the first place. Thus after provisioning new site content types or site columns, you must add some sample content and then do a full recrawl of the applicable content source.
Verifying that the full crawl of the SharePoint sites content source finished without errors completes the Central Admin configuration. Now it's time to configure the ootb Search Core Results web-part to become the customized My Tasks web-part.
Open a team-site and add the Search Core Results web-part to a page. Switch to page edit mode and select 'Edit Web Part' to open the Search Core Results settings panel. Rename the web-part 'Title' to Task Rollup (cross-site) and set the 'Cross Web-Part Query ID' to User query and 'Fixed Keyword Query' to scope: "TaskRollup" as shown here:

The Search Core Results web-part requires a user query, or a configured fixed or appended query, to actually perform a search. No configured or no user query will just show a message asking for query input. The cross-page query ID setting User query is chosen here for reasons explained later.
If you want to further limit what tasks are shown in the My Tasks web-part, just add more query keywords to the 'Append Text to Query' setting as shown here:

The My Tasks web-part will show the two task fields 'Status' and 'Assigned to' in the task list. Any managed crawled property can be added to the search results by configuring the 'Fetched Properties' setting. Add the following XML <Column Name="AssignedTo"/> <Column Name="TaskStatus"/> as shown here:

You need to uncheck the 'Use Location Visualization' setting to enable the controls for customizing the result set and XSL formatting. See A quick guide to CoreResultsWebPart configuration changes in SharePoint 2010 by Corey Roth to learn more about the new search location concept in SharePoint 2010. Read all his Enterprise Search posts for an excellent introduction to the improved SharePoint 2010 search services and web-parts.
After adding 'TaskStatus' and 'AssignedTo' to the fetched properties, you will also need to customize the XSL used to format and show the search results to also include your extra task fields. Click the 'XSL Editor' button in the 'Display Properties' section of the web-part settings panel, and add the fields to the match="Result" xsl:template according to your design. Note that the property names must be entered in lower case in the XSL.
The astute reader will have noticed the nice grouping of the search results. This is done using the Muenchian method as SharePoint 2010 still uses XLST 1.0, thus no simple XSLT 2.0 xsl:for-each-group. The customized "My Tasks" results XSL creates a key called 'tasks-by-status' that selects 'Result' elements and groups them on the 'taskstatus' field as shown here:
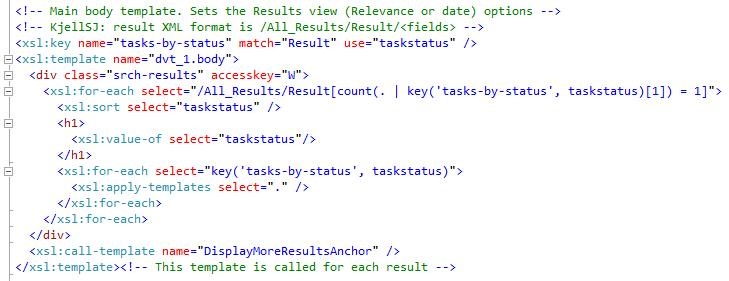
Again, note the requirement for lower case names for the fetched properties when used in the XSL. Use the <xmp> trick to see the actual result XML.
The final part of the puzzle is how to turn the cross-site task list into a personal task list. Unfortunately, the [Me] and [Today] filter tokens cannot be used in the enterprise search query syntax, so some coding is required to add such dynamic filter tokens. Export the customized Search Core Results web-part to disk to start packaging into a WSP solution.
Create a new TaskRollupWebPart web-part SPI in your web-parts feature in Visual Studio 2010. Make the new web-part class inherit from CoreResultsWebPart in the Microsoft.Office.Server.Search assembly. Override the methods shown here to add dynamic filtering of the query through the SharedQueryManager for the web-part page:
namespace PuzzlepartTaskRollup.WebParts
{
[ToolboxItemAttribute(false)]
public class TaskRollupWebPart :
Microsoft.Office.Server.Search.WebControls.CoreResultsWebPart
{
QueryManager _queryManager;
protected override void OnInit(EventArgs e) {
base.OnInit(e);
_queryManager = SharedQueryManager.GetInstance(this.Page).QueryManager;
}
protected override System.Xml.XPath.XPathNavigator GetXPathNavigator(string viewPath)
{
SPUser user = SPContext.Current.Web.CurrentUser;
_queryManager.UserQuery = string.Format("scope:\"TaskRollup\" AssignedTo:\"{0}\"",
user.Name);
return base.GetXPathNavigator(viewPath);
}
protected override void CreateChildControls()
{
base.CreateChildControls();
//debug info
//Controls.Add(new Label { Text = string.Format("FixedQuery: {0}<br/>
AppendedQuery: {1}<br/>UserQuery: {2}",
FixedQuery, AppendedQuery, _queryManager.UserQuery) });
}
}
}
The code in GetXPathNavigator is what adds the current user to the QueryManager.UserQuery to filter tasks based on the assigned user by [me]. There are five query objects available on a search web-part page, where QueryId.Query1 is the default. This is also what is exposed in the web-part settings as the 'User Query' option. Use the GetInstance(Page, QueryId) overload in SharedQueryManager to get at a specific cross-page query object.
Replace the content of the TaskRollupWebPart.webpart file with the exported Search Core Results configuration. This will ensure that all the configuration done to customize the ootb web-part into the My Tasks web-part is applied to the new TaskRollupWebPart. A small change is needed in the metadata type element to load the new TaskRollupWebPart code rather than the CoreResultsWebPart code:
<webParts>
<webPart xmlns="http://schemas.microsoft.com/WebPart/v3">
<metaData>
<type name="PuzzlepartTaskRollup.WebParts.TaskRollupWebPart,
$SharePoint.Project.AssemblyFullName$" />
<importErrorMessage>$Resources:core,ImportErrorMessage;</importErrorMessage>
</metaData>
Build the feature and deploy the package to your test site from Visual Studio 2010. Add the web-part to a page and verify that you get only your tasks as expected.
I know that this seems like a lot of work, but a search-driven web-part is easily created and tested before lunch. The inevitable styling & layout using XSL and CSS is what will burn hours, as usual.
A drawback of search driven web-parts or code is the delay before new/updated content is shown due to the periodical crawling schedule, typically five or ten minutes. On the positive side, the results will be automatically security trimmed for you based on the logged on user - no authentication hassles or stored username password required as with the XSL List View.
Note that most enterprise search classes are still sealed in SharePoint 2010 as in SharePoint 2007, except the CoreResultsWebPart and some new classes, so you're limited to what customizations can be achieved with configuration or the SharedQueryManager. Search driven web-parts works equally well in SharePoint 2007, except that there is no SharedQueryManager, but rather the infamous search results hidden object (SRHO) which is unsupported.
Recommended: SharePoint Search XSL Samples and the Search Community Toolkit at CodePlex.