As the support for WS-I Basic Profile 1.x compliant web-services is quite limited in Flex, I had to make ASMX-style clients works. What made it worse, is that there is a bug in Flex regarding the support for xsd:import: Flex will repeatedly request the XSD files on .LoadWSDL(), causing bad performance for the web-service and the client. Use Fiddler to watch all the HTTP GETs issued by Flex. The solution is to ensure that the generated WSDL is a single file, without any xsd:import, and this is just what a classic .NET 2 ASMX web-service provides.
WCF has good support for migrating ASMX web-services to WCF, and this feature can also be used to actually expose a native WCF service also as an ASMX web-service. Start by adding the classic [WebService] and [WebMethod] attributes to your service interface:
[ServiceContractAttribute(Namespace = "http://kjellsj.blogspot.com/2006/11",
Name = "IProjectDocumentServices")]
[ServiceKnownTypeAttribute(
typeof(DNVS.DNVX.eApproval.FaultContracts.DefaultFaultContract))]
[WebService(Name = "ProjectDocumentServices")]
[WebServiceBinding(Name = "ProjectDocumentServices",
ConformsTo = WsiProfiles.BasicProfile1_1, EmitConformanceClaims = true)]
public interface IProjectDocumentServices
{
[OperationContractAttribute(Action = "GetDocumentCard")]
[FaultContractAttribute(
typeof(DNVS.DNVX.eApproval.FaultContracts.DefaultFaultContract))]
[WebMethod]
DocumentCardResponse GetDocumentCard(KeyCriteriaMessage request);
. . .
Note that there is no need for adding [XmlSerializerFormat] to the [ServiceContract] attribute, just leave the WCF service as-is. Note also that you must specify the web-service binding Name parameter to avoid getting duplicate wsdl:port elements in the generated WSDL file. You should apply the [WebService] attribute using the same Name and Namespace parameters as for the [WebServiceBinding], to the class implementing the service. If not, you might get a wsdl:include and and xsd:import in the generated WSDL file.
Then add a new .ASMX file to the IIS host used for your WCF service, using the service implementation assembly to provide the web-services. I added a file called "ProjectDocumentWebService.asmx" with this content:
<%@ WebService Language="C#" Class="DNVS.DNVX.eApproval.ServiceImplementation
.ProjectDocumentServices, DNVS.DNVX.eApproval.ServiceImplementation" %>
That's it. You now have a classic ASMX web-service at your disposal. WCF supports running WCF services and ASMX web-services side-by-side in the same IIS web-application: Hosting WCF Side-by-Side with ASP.NET.
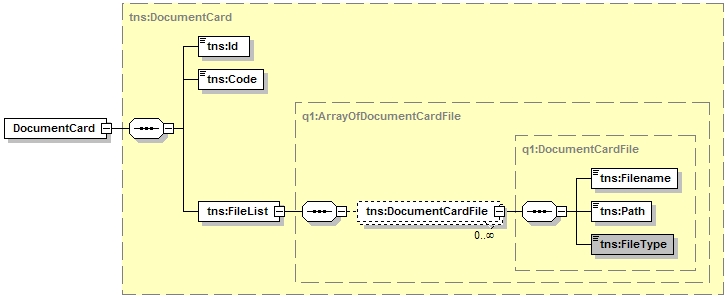
Most likely you must also apply [XmlElement], [XmlArray] and [XmlIgnore] at relevant places in your message and data contracts to ensure correct serialization (XmlSerializer) and ensure consistent naming for both WCF and ASMX clients/proxies. Remember that the XmlSerializer works only with public members and that it does not support read-only properties. Do not mark message and data contract classes as [Serializable] as this changes the wire-format of the XML, which might cause problems in Flex 2.Note that the ASMX-style WSDL will not respect the [DataMember (IsRequired=true)] setting or any other WCF settings because it uses the XmlSerializer and not the DataContractSerializer. You will get minOccurs=0 in the generated WSDL for string fields, as string is a reference type. This is because the XmlSerializer by default makes reference types optional, while value types by default are mandatory. Read more about XmlSerializer 'MinOccurs Attribute Binding Support' at MSDN.
Note the difference between optional elements (minOccurs) and non-required data (nillable) in XSD schemas. This is especially useful in query specification objects, make all the elements optional and apply only the specified elements as criteria - even "is null" criteria.
The unsolved WSDL problem described in my last post is no longer an issue for ASMX-clients, as the WSDL generated by the classic ASMX web-service of course natively supports .NET 2 proxies generated by WSDL.EXE. The issue with the Name parameter for the [CollectionDataContract] attribute is still a problem, it must be removed.
Thanks to Mattavi for the "Migrating .NET Remoting to WCF (and even ASMX!)" article that got me started.