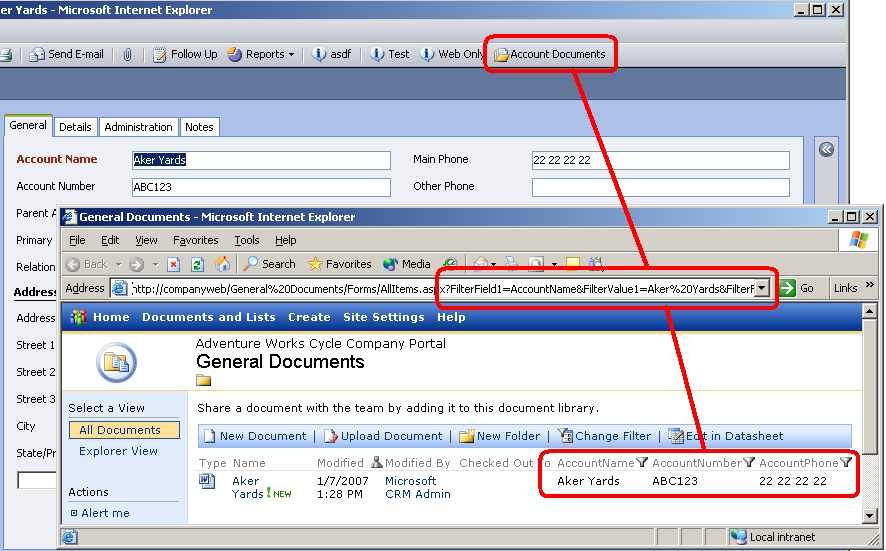
Editing the WCF client and server configuration files is a quite daunting task, but luckily the new version of WSSF offers nice wizards for configuring security for your services. The 'WCF security' menu allows you to easily add support for the most common providers: client X.509 certificates, Kerberos, ADAM, SQL Server, ActiveDirectory, server certificate.

Among the available providers, the Kerberos provider is the simplest to use if you don't want to use a certificate nor HTTPS/SSL, or you want/has to use Cassini (the VS2005 developer web-server), as shown in the figure (click to enlarge):

The wizard is straightforward, just remember to include metadata (MEX) in your service if you want to expose a WSDL file. Adding a list of authorized clients is not mandatory for this security mode. I recommend that you delete all content in the <system.serviceModel> element in the service config file before using the 'WCF Security' menu. This ensures a clean configuration settings section afterwards.
I then updated the service reference of our SmartClient application to get the correct settings for the client config file. This step is important, as the common configuration settings must be equal on both client and server for WCF communication to work.
With all the configuration finished, it was time for some testing. I got this error when invoking a WCF operation:
System.ServiceModel.Security.MessageSecurityException: The token provider cannot get tokens for target 'http://localhost.:1508/eApproval.Host/ProjectDocumentServices.svc'. ---> System.IdentityModel.Tokens.SecurityTokenValidationException: The NetworkCredentials provided were unable to create a Kerberos credential, see inner execption for details. ---> System.IdentityModel.Tokens.SecurityTokenException: InitializeSecurityContent failed. Ensure the service principal name is correct. ---> System.ComponentModel.Win32Exception: No credentials are available in the security package
--- End of inner exception stack trace ---
My client config file contained these security settings, which to me looked fine and dandy:
<security mode="Message">
<transport clientCredentialType="Windows" proxyCredentialType="None" realm="" />
<message clientCredentialType="Windows" negotiateServiceCredential="false" algorithmSuite="Default" establishSecurityContext="false" />
</security>
My suspects were the extra <message> element attributes not covered in Keith Brown's "Security in WCF" article: negotiateServiceCredential and establishSecurityContext. As usual with new Microsoft technology, the online help is rather lame, so some research was required.
Googling lead me to this excellent article by Michèle Leroux Bustamante: "Fundamentals of WCF Security" (6 pages). The 'Service Credentials and Negotiation' section contained the explanation for my error: "When negotiation is disabled for Windows client credentials, a Kerberos domain must exist". So by turning service identity negotiation on in both the client and the server config files, my client can now communicate securely with our WCF service. I also recommend turning on the 'secure session' context for better performance, unless your service is rarely used by the client.
A confusing part of the client side authentication settings for the 'Windows' security mode is the <endpoint/identity> element, which will typically contain your "user principal name" (UPN) in the <userPrincipalName> element when hosting with Cassini or self-hosting. The identity setting is not for specifying who the client user is, but for identityfying and authenticating the service itself. If you use IIS as the host, the identity must contain the "service principal name" (SPN). Note that if your IIS app pool identity is not NETWORK SERVICE, you must typically create the SPN explicitly.
The <identity> element is only used with NTLM or negotiated security. If you use non-negotiated security such as direct Kerberos, this element is not supported.
The security config now looks like this (server side settings):
<bindings><wsHttpBinding>
<binding name="BrokeredAuthenticationKerberosBinding">
<security mode="Message"> <message clientCredentialType="Windows" negotiateServiceCredential="true" establishSecurityContext="true" />
</security>
</binding>
</wsHttpBinding>
</bindings>
Checking the on-the-wire format with Fiddler shows that the request and response messages now are encrypted; without using HTTPS or SSL transport level security:

The system provided bindings and the WSSF wizards do a good job in guiding you in the WCF settings jungle; but when your automated guide gets lost, you'd better have some survival skills. Knowing the inner workings of WCF is a must for professional service developers, and I strongly recommend reading Michèle's article. The same goes for her blogs and the WCF stuff at IDesign.
Fiddler is highly recommended and can be downloaded from http://www.fiddlertool.com/fiddler/.